
While existing image-text alignment models reach high quality binary assessments, they fall short of pinpointing the exact source of misalignment.
In this paper, we present a method to provide detailed textual and visual explanation of detected misalignments between text-image pairs. We leverage large language models and visual grounding models to automatically construct a training set that holds plausible misaligned captions for a given image and corresponding textual explanations and visual indicators. We also publish a new human curated test set comprising ground-truth textual and visual misalignment annotations.
Empirical results show that fine-tuning vision language models on our training set enables them to articulate misalignments and visually indicate them within images, outperforming strong baselines both on the binary alignment classification and the explanation generation tasks.
Our fine-tuned model results on our generated training data. Please note the precision of our produced Textual-Visual feedback, which includes: a concise explanation of the misalignment, a misalignment cue that pinpoints the contradictory source in the caption, and a labeled bounding box.
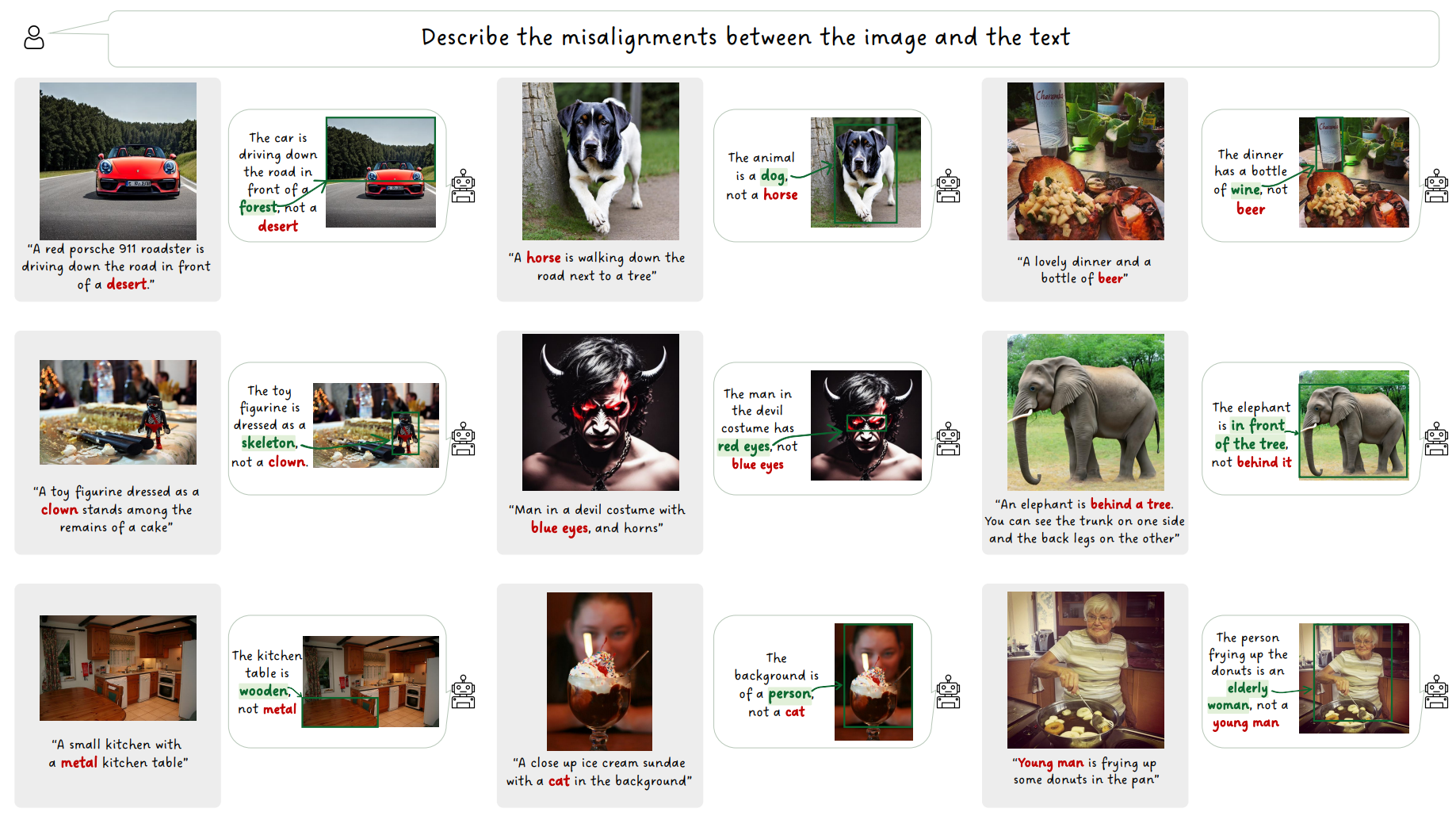
We evaluate our model’s generalization capabilities on ‘in-the-wild’ Text-to-Image (T2I) generations from , created using Adobe Firefly, Composable Diffusion, and Stable Diffusion versions 1.0 and 2.1.

For each aligned image/caption pair we define a misalignment category (object , attribute, action, or spatial relations).
Per chosen misalignment candidate, we instruct PaLM 2 API with few-shot prompts to automatically generate:
(A) Contradiction caption that introduces the target misalignment.
(B) Detailed explanation of the contradiction (feedback).
(C) Misalignment cue that pinpoints the contradictory element in the caption.
(D) a label for the visual bounding box to be placed on the image.
To create the bounding-box misalignment, we employ GroundingDINO visual grounding model.

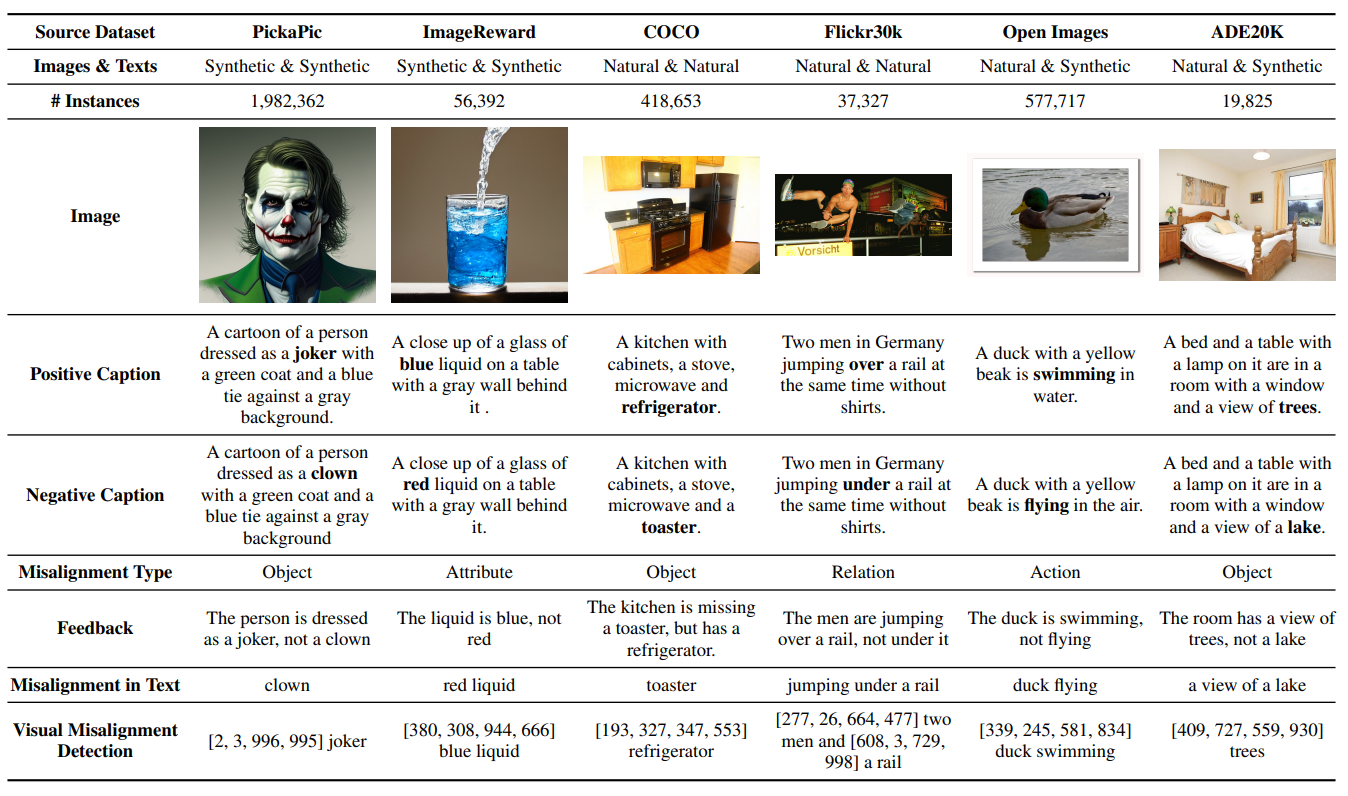
We compile a set of over a million positive image-text pairs, consisting of synthetic and natural images. Approximately 65\% of our examples consist of synthetic and real images, from PickaPic, ImageReward, Flickr30k, COCO , OpenImages and ADE20K.
Using our ConGen-Feedback method, we generated our training dataset to fine-tune PaLI model to predict a full Textual-Visual feedback.
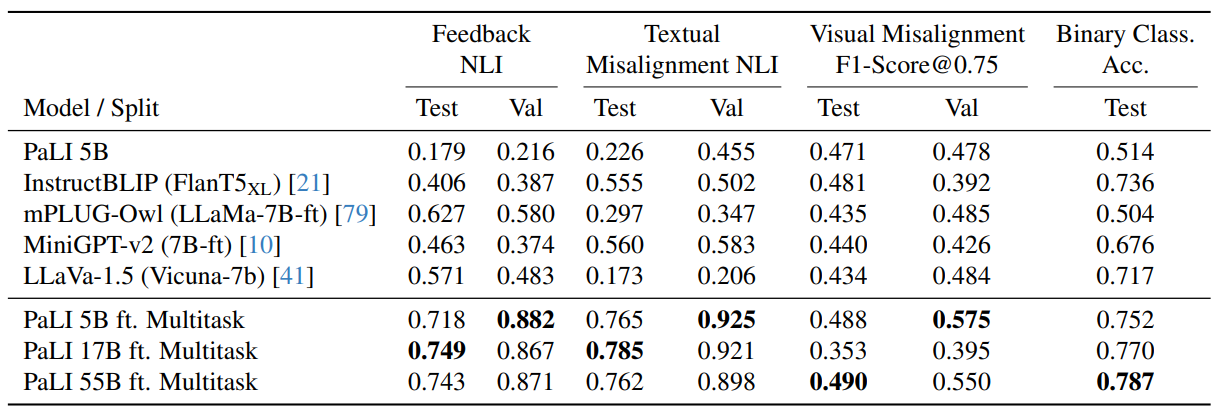
Textual-Visual feedback results on SeeTRUE-Feedback (Test split) and TV-Feedback dataset (Val split). Our PaLI models fine tuned on TV-Feedback dataset outperform the baselines on all metrics.
Using BART-NLI we measure feedback quality by treating ground truth as the ’premise’ and model predictions as the ’hypothesis’ extracting an entailment score as semantic alignment.
We evaluate the model’s bounding box generation using F1-Score@0.75 (indicating an IoU threshold of 0.75).
@misc{gordon2023mismatch,
title={Mismatch Quest: Visual and Textual Feedback for Image-Text Misalignment},
author={Brian Gordon and Yonatan Bitton and Yonatan Shafir and Roopal Garg and Xi Chen and Dani Lischinski and Daniel Cohen-Or and Idan Szpektor},
year={2023},
eprint={2312.03766},
archivePrefix={arXiv},
primaryClass={cs.CL}
}